简介
如果服务器硬盘坏了,数据恢复的可能性存在,但并不是百分之百。
首先需要知道的是,数据恢复的难度与硬盘故障的类型和程度密切相关。如果是物理损坏,比如电路板故障或者盘片划伤等,恢复的难度会非常大,而且通常无法保证能够完全恢复所有数据。如果是逻辑损坏,比如文件系统错误或者病毒攻击等,恢复的难度相对较小,但也需要根据具体情况而定。
针对服务器数据恢复,以下是一些可能的步骤:
- 备份数据:
- 在服务器硬盘损坏后,首先要做的是备份所有数据。这可以通过使用专业的数据恢复设备或者硬盘拷贝机来实现。要确保备份的数据完整性和准确性,需要在备份过程中仔细操作并检查。
- 修复硬盘:
- 对于物理损坏的硬盘,需要进行修复。这通常包括更换电路板、修复盘片或者更换整个硬盘等。在这个过程中,需要非常小心,以免对硬盘造成更大的损坏。
- 数据恢复:
- 在备份完数据并修复好硬盘后,可以开始进行数据恢复。这通常包括在专业的数据恢复设备上对硬盘进行镜像备份、分析raid信息、尝试恢复丢失的数据等。这个过程需要专业的技能和经验,不能随意操作。
需要注意的是,在数据恢复过程中,任何操作都可能对原始数据造成破坏,因此最好避免在原盘上进行数据分析、重组等操作。同时,如果发现有无法恢复的数据,不要继续尝试,以免对数据造成更大的破坏。
以上是常规磁盘数据恢复过程,由专业的服务器运维工程师操作。
当样本下机fastq.gz文件通过以上专业方式依然无法恢复时,我们可以通过生信方式尽量多的从损坏文件中获取有用信息,尽可能降低损失。
损坏文件修复
整体修复流程
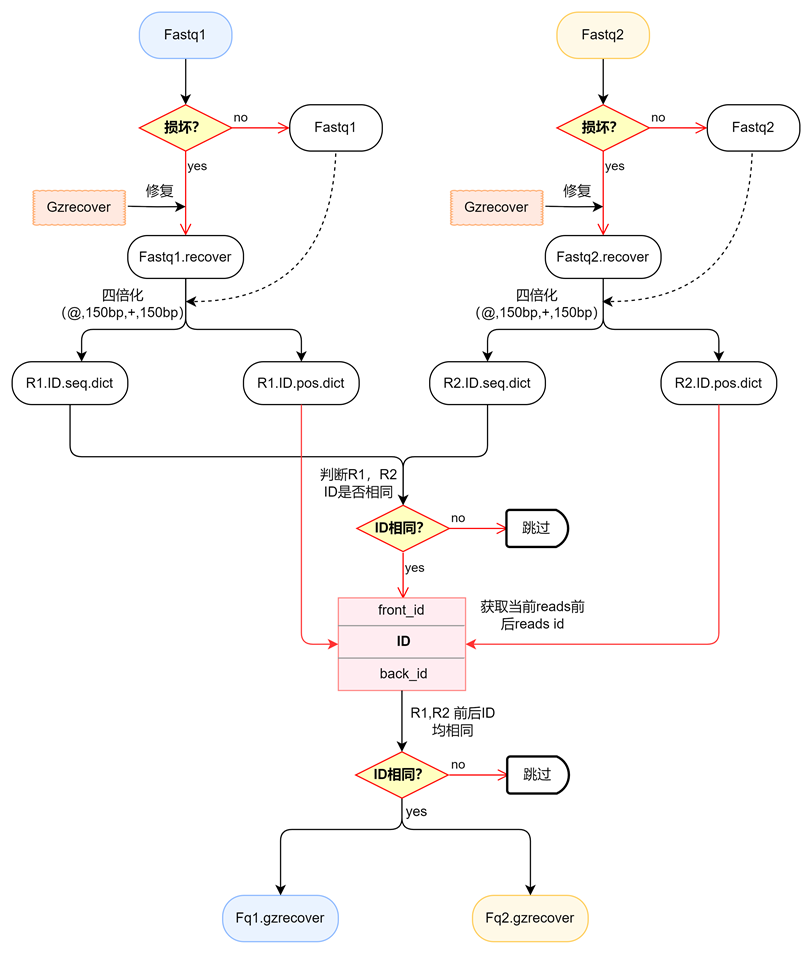
损坏fastq.gz文件修复整体流程如下:
gzip压缩原理
根据gzip算法的压缩原理,已知修复一个损坏的gzip文件的关键环节在于找到下一个正常压缩包的起始点。根据结构图中的信息可知,每个压缩包的开始结构中有是否到达尾部标志、使用的哈夫曼树类型、以及3个哈夫曼树的树元素个数等。如果某个gzip文件中间有一个坏扇区,要找到坏扇区后的一个正常起点,仅需按位右移,一直移位到可以正常解压的某个位,就可能找到了正确的压缩包起始。而根据gzip文件的压缩作业窗口为32KB大小推算,这个遍历不会超过64KB即可找到。在内存中快速循环可以很快找到,但需要有明确的判断错误的方法。
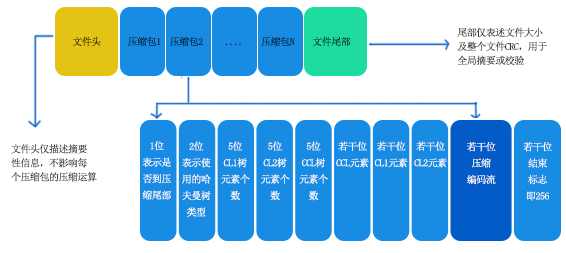
理论上我们可以对gzip的源码(C语言)做修改,进行遍历找出损坏点后的有用数据。但实际上可操作性较低,我们只能借助其它现成的工具。
fastq.gz文件损坏判断
使用seqkit stat命令,查看fastq文件基本统计信息是否正常输出;
1 | seqkit stat -a WL102PD1Mg_HN2HKCCXY-L7_R1.fastq.gz |
gzrecover 软件
gihub上开源的 gzrecover软件可以从已损坏的gzip文件中提取任何可读内容,用于损坏gz文件修复。
软件官网及参数如下:
1 | https://github.com/arenn/gzrt |
注意事项:
- 未损坏的gz文件,不建议使用gzrecover软件处理;
- gzrecover恢复后的内容中,依然有乱码,需要进一步处理;
1
2
3
4
5
6
7
8
9
10# 乱码情况可能出现中文件的开头、中间等地方
1 7jNPᅢ<81>S<C0>^Mo"<F3>^L<D8><FB>4<88>5^0^D]z<U+063B>^Z<D8>|_R<B2><98>y<FE>[^BGU<E0><D9>^FS #Pboe<C2>[i:<B9>?U<F5>"<85><C8>HV<A8>_1^F^ZM<E5><E2>T^Y<8E>8+KՔh<9F>J^P~<A9>
2 <E4><A0>^MݏF<DF>^PK%^]<D2>;HbC<F4>ESCK<D5>(<8B>^Nt<89>'X<B6>^X^AY<8F><D7>W^]<AD>t^]C<87>j<BF>X<B6>^X^AY<8F><D7>ESC<D9><CF><D5>=^^<99>^^<99>^^<99><88><8E>^M<F2>^ER<9A>0X<9D>^Y^@
3 GGTCTGTTGAGGTCGTCAAAAGGGACAGGATCCTCTTAATTGAATTAAACCTAAATTTACCCCAGAGCTATATGAGGGAGAGTTAGATACCTGAAAAATTGAGGATTTACCTTGCCCCAAGAAAAGATGGAATAATATGTTTGGTATAGA
4 +
5 FFFFFFFFFFFF:FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF:FFFFFFFFFFFFFFFFFFFF
6 @A00459:269:H5HHMDSX3:2:1101:11912:1485 2:N:0:CATTGCCT+GTTCTCAG
7 GGTCAAGGCTGGACCCATCCCCATCTCACCAGCAGCACAGTCAGATTCAGACACAGGTATTCAACTTTGCAACACACTGTGCCTCACGGCCAGTGTGCTCAACATCAGAAATCAAATAGAAAATCCCACATTCTAAGATTCATATCCATC
8 +
fastq信息提取
损坏的fastq.gz文件经过gzrecover修复后,使用python 程序能够正常读取到文件结尾。
正常的fastq文件是4行为一个单元(unit):
- 第1行主要储存序列测序时的坐标等信息;
- 第2行是测序得到的序列信息;
- 第3行以“+”开始,可以储存一些附加信息,一般是空的;
- 第4行储存的是质量信息;
1
2
3
4@ST-E00126:128:HJFLHCCXX:2:1101:7405:1133
TTGCAAAAAATTTCTCTCATTCTGTAGGTTGCCTGTTCACTCTGATGATAGTTTGTTTTGG
+
FFKKKFKKFKF<KK<F,AFKKKKK7FFK77<FKK,<F7K,,7AF<FF7FKK7AA,7<FA,,
fastq.gz文件损坏后,可能会导致fastq文件内容部分丢失,比如缺失reads中的某一两行。因此,对gzrecover软件修复的fastq文件,在正式使用前,还需要进行预处理:
- 将fastq文件内容按照四行(@,150bp序列,+,150个质量信息)为一个单元进行整理,如果四行中缺少某行(或某部分),则整个单元丢弃;
- reads1与reads2 ID名称对应,未对应的则丢弃;
- 对应上的ID 在fastq1、fastq2文件中前后相邻的ID也要一一对应,否则丢弃;
- 经过两次过滤后,最终保留的reads,可正常使用。
参考使用脚本如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import sys
import re
import os
import gzip
import argparse
from collections import deque
from multiprocessing import Pool
usage = '''
Description:
Designed to extract reads from fastq (fastq.gz,fastq.recovered) files!\n
'''.format(src=(__file__[__file__.rfind(os.sep) + 1:]))
def options():
parser = argparse.ArgumentParser(formatter_class= argparse.RawTextHelpFormatter,description=usage)
parser.add_argument("-1",'--fq1', help='Input fastq R1 file', dest='fq1', type=str, action='store', required=True)
parser.add_argument("-2",'--fq2', help='Input fastq R2 file', dest='fq2', type=str, action='store', required=True)
parser.add_argument("-s",'--sample', help='Input sample name,(default: %(default)s)', dest='sample', type=str, action='store', default="Test")
args = parser.parse_args()
return args
# reads 4行判断(边读取边判断);
def get_fq_dict(in_file):
fq_unit_dict = {} # id: {seq,plus,qua,pos}
pos_id_dict = {} # pos:id
ele_deque = deque()
if in_file.endswith(".gz"): # gz压缩格式
inf = gzip.open(in_file,"rt")
else:
inf = open(in_file,"r",encoding='latin-1') # latin-1 for qsub
pos = 0 # reads 起始位置
for line in inf:
line = line.strip()
ele_deque.append(line)
if len(ele_deque) == 4:
if ele_deque[0].startswith("@") and ele_deque[2] == "+" and len(ele_deque[1]) == 150 and len(ele_deque[3]) == 150:
key = re.split(r"\s+",ele_deque[0])[0].replace("@","") # 提取read1,read2 名称共有部分;
ele_deque.append(pos)
fq_unit_dict[key] = tuple(ele_deque.copy()) # to tuple
pos_id_dict[pos] = key
ele_deque.clear()
pos += 1
else:
ele_deque.popleft()
inf.close()
return fq_unit_dict,pos_id_dict
def get_pos_info(all_fq_nums,r_pos,fq_pos_id_dict):
fq_nums = all_fq_nums - 1
if fq_nums > r_pos > 0:
r_front_pos = r_pos - 1
r_back_pos = r_pos + 1
elif r_pos == 0:
r_front_pos = 0
r_back_pos = r_pos + 1
else:
r_front_pos = r_pos - 1
r_back_pos = fq_nums
r_front_id = fq_pos_id_dict[r_front_pos]
r_back_id = fq_pos_id_dict[r_back_pos]
return r_front_id,r_back_id
def run_process(fq1_file,fq2_file):
files_list = [fq1_file,fq2_file]
tmp_list = []
pool = Pool(2)
for file in files_list:
tmp_list.append(pool.apply_async(get_fq_dict,args=(file,)))
pool.close()
pool.join()
fq1_unit_dict, fq1_pos_id_dict = tmp_list[0].get()
fq2_unit_dict, fq2_pos_id_dict = tmp_list[1].get()
return fq1_unit_dict, fq1_pos_id_dict,fq2_unit_dict, fq2_pos_id_dict
def main():
args = options()
fq1_file = args.fq1
fq2_file = args.fq2
prefix = args.sample
outfq1_file = f"{prefix}_gzrecover_R1.fastq.gz"
outfq2_file = f"{prefix}_gzrecover_R2.fastq.gz"
log_file = f"{prefix}.gzrecover.log"
fq1_unit_dict,fq1_pos_id_dict,fq2_unit_dict,fq2_pos_id_dict = run_process(fq1_file,fq2_file)
fq1_nums = len(fq1_unit_dict)
fq2_nums = len(fq2_unit_dict)
id_match_num = 0
id_pos_match_num = 0
with gzip.open(outfq1_file,'wt') as outfq1, gzip.open(outfq2_file,'wt') as outfq2,open(log_file,'w') as outlog:
outlog.write(f"sample\tfq1_num\tfq2_num\tid_match_nums\tid_match_ratio\tid_pos_match_num\tid_pos_match_ratio\n")
for key in fq1_unit_dict:
if key not in fq2_unit_dict: # 不配对reads
continue
id_match_num += 1 # ID 配对reads
r1_list = fq1_unit_dict[key]
r2_list = fq2_unit_dict[key]
r1_pos = r1_list[-1]
r2_pos = r2_list[-1]
r1_front_id, r1_back_id = get_pos_info(fq1_nums,r1_pos,fq1_pos_id_dict)
r2_front_id, r2_back_id = get_pos_info(fq2_nums,r2_pos,fq2_pos_id_dict)
if r1_front_id != r2_front_id or r1_back_id != r2_back_id:
#print(key)
continue
id_pos_match_num += 1 # ID及位置均配对reads
read1_info = "\n".join(r1_list[0:4])
read2_info = "\n".join(r2_list[0:4])
outfq1.write(f"{read1_info}\n")
outfq2.write(f"{read2_info}\n")
if fq1_nums < fq2_nums:
id_pos_match_ratio = id_pos_match_num/fq2_nums
id_match_ratio = id_match_num/fq2_nums
else:
id_pos_match_ratio = id_pos_match_num/fq1_nums
id_match_ratio = id_match_num/fq1_nums
outlog.write(f"{prefix}\t{fq1_nums}\t{fq2_nums}\t{id_match_num}\t{id_match_ratio:.2f}\t{id_pos_match_num}\t{id_pos_match_ratio:.2f}\n")
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
sys.stderr.write("User interrupt me! ;-) See you!\n")
sys.exit(0)
1 | # 使用示例 |
碎碎念
在日常工作中,文件损坏的概率很小。即使文件损坏了,一般也是重新测序。然而现实总有些不同寻常,对小概率事件进行非常规操作。同时,也从侧面表明日常数据管理和备份的重要性。